WebMagic的基础使用
官方中文文档:http://webmagic.io/
安装WebMagic
1 | <dependency> |
编写TestProcessor定制爬虫逻辑
1 | package test.webmagic.com.test; |
编写TestPipeline定制抽取的结果处理类
1 | package test.webmagic.com.test; |
启动看看效果
第一页标题
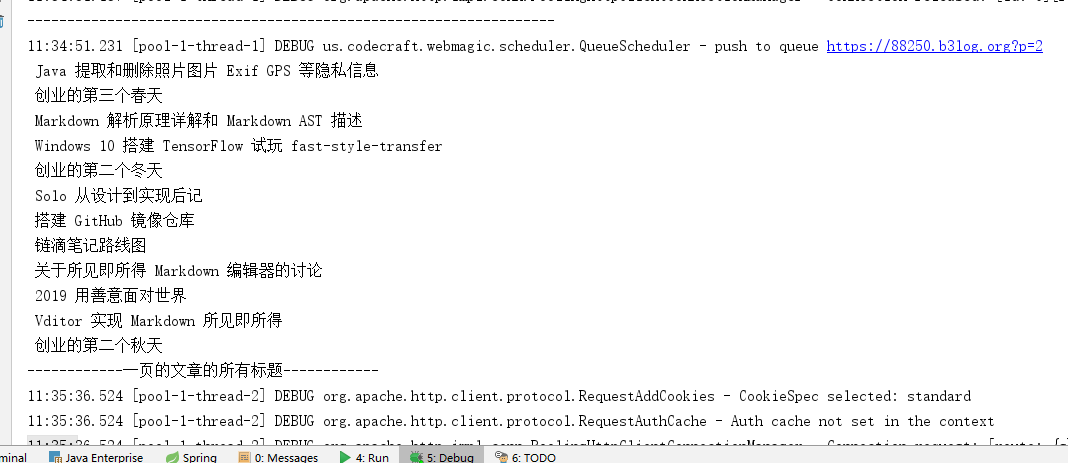
第二页标题

1 | <dependency> |
1 | package test.webmagic.com.test; |
1 | package test.webmagic.com.test; |